
 2021-01-17
2021-01-17
Średnie obciążenie systemu, stany procesów w systemie Linux i kilka mitów związanych z loadavg
W moim doświadczeniu zawodowym często prowadzę rekrutacje, których częścią są pytania związane z systemami z rodziny Linux. Jednym ze standardowych pytań jest pytanie o statystykę systemową, jaką jest średnie obciążenie systemu. Niestety zdarza się, także u osób z naprawdę imponującym doświadczeniem zawodowym, iż kandydat nie potrafi poprawnie jej nakreślić. Dlatego dziś o statystyce.
W moim doświadczeniu zawodowym dosyć często mam okazję prowadzić rekrutacje, których częścią są pytania związane z systemami z rodziny Linux. Jednym ze standardowych pytań jest pytanie o istotną (aczkolwiek wcale nie mówiącą tak dużo) statystykę systemową, jaką jest średnie obciążenie systemu (ang. load average, skrótowo zapisywane jako loadavg). Niestety zdarza się, także u osób z naprawdę imponującym doświadczeniem zawodowym, iż kandydat nie potrafi poprawnie opisać i interpretować informacji płynących z load average.
Postanowiłem więc zadać sobie pytanie, z czego to wynika. Sprawdziłem zaufane źródła prawdy, takie jak wyszukiwarki internetowe (DuckDuckGo i Google) oraz Wikipedię. Ta ostatnia de facto najpełniej opisała tę statystykę. Niestety w internecie jest bardzo dużo uproszczeń lub wręcz błędów na jej temat. Nie ma w tym nic dziwnego, gdyż same podręczniki systemowe często w sposób niepełny podają, czym ta statystyka jest.
By omówić średnie obciążenie systemu, należy się jednak cofnąć i wprowadzić minimum teorii dotyczącej procesów i ich stanów w systemie Linux. Pozwoliłem sobie zaczerpnąć z sprawdzonego źródła wiedzy, jakim jest podręcznik szkoleniowy EuroLinux z administracji Enterprise Linuksem na poziomie podstawowym.
Stany procesów w systemie Linux
Fragmenty z podręcznika szkoleniowego Enterprise Linux Administration I
Procesy mogą znajdować się w różnych stanach. By móc zrozumieć wyjścia komend opisujących procesy, należy najpierw poznać te stany. Poniższa tabela prezentuje listę wyświetlanych flag z nazwami procesu oraz objaśnieniem, jaki stan w wewnętrznych strukturach jądra jest przypisany zadanemu stanowi.
| Flaga | Nazwa (ang) | Nazwa w jądrze i objaśnienie |
|---|---|---|
| R | Running or Runnable | TASK_RUNNING. Proces jest wykonywany lub czeka na wykonanie. Może wykonywać się w przestrzeni użytkownika (kod użytkownika) lub w przestrzeni jądra (kod jądra) |
| S | Interruptible sleep | TASK_INTERRUPTIBLE. Proces czeka na spełnienie jakiegoś warunku, np. dostępu do zasobu lub sygnał (takim sygnałem jest np. wyjście procesu dziecka) |
| D | Uninterruptible sleep | Uninterruptible sleep| TASK_UNINTERRUPTIBLE. Proces śpi jak przy fladze S, jednak nie będzie odpowiadał na sygnały. Używane, gdy przerwanie procesu lub jego zabicie może wprowadzić urządzenia lub proces w niezdefiniowany stan. Z reguły używany podczas operacji I/O. Proces wpada w ten stan także, gdy jego strony pamięci są zrzucane lub wczytywane do pamięci rozszerzonej tj. „swappowane” |
| T | Stopped | TASK_STOPPED. Proces został zatrzymany przez odpowiednie sygnały. Może zostać przywrócony przez inny sygnał |
| t | Traced | TASK_TRACED. Proces jest debugowany, jego wykonanie jest śledzone. Jest on na chwilę zatrzymywany w celu badania jego stanu |
| Z | Zombie | EXIT_ZOMBIE. Proces dziecko zakończył swoje działanie i chce poinformować rodzica o swoim kodzie wyjścia. Niestety czasem rodzice nie obsługują poprawnie swoich dzieci. W takim wypadku z dziecka tworzy się zombie |
| X | Dead | EXIT_DEAD. Proces zakończył swoje działanie, rodzic uprzątnął swoje dziecko. Wszystkie zasoby procesu są uwalniane. W normalnych warunkach ten stan nie powinien być widoczny |
Oprócz wyżej wymienionych flag, mamy także flagi K od „killable”, czyli procesu w stanie flagi D, który może zostać zabity, a także flagę I od „idle”, czyli bezczynny. Rzadko jednak obserwuje się procesy w tym stanie, gdyż są one z reguły wykonywane przez wewnętrzne procesy jądra.
Poniższy diagram prezentuje różne stany procesów i podstawowe interakcje między nimi.
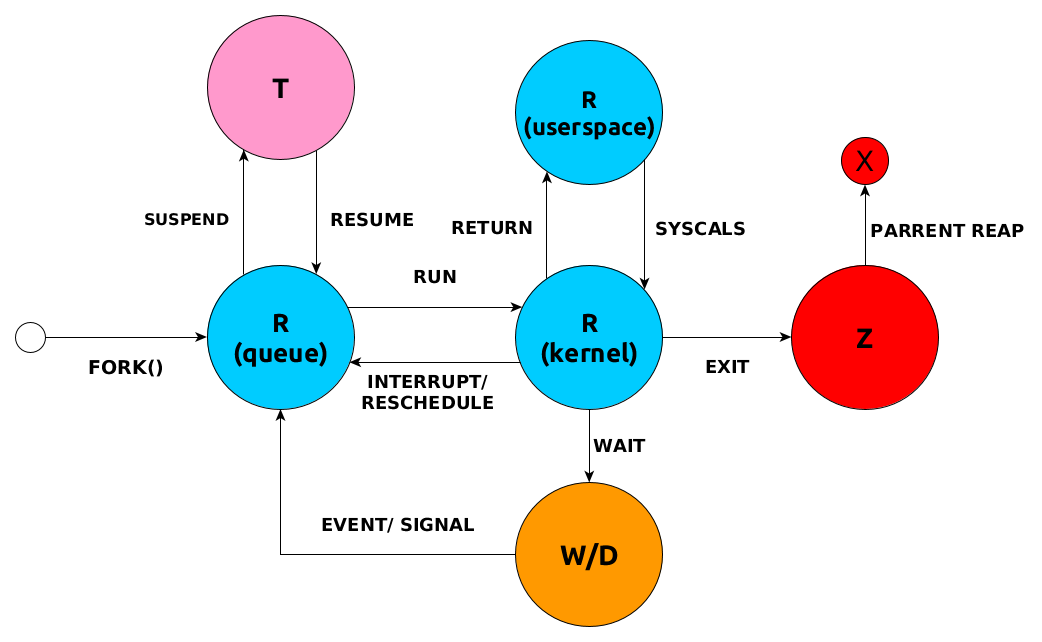
Gdzie zdefiniowane są stany procesów?
Sam proces w systemie Linux jak i stany procesów są zdefiniowane w źródłach jądra w pliku source/include/linux/sched.h (sched jako skrót od ang. scheduler, czyli planisty systemowego). Pozwolę sobie wkleić fragment kodu definiujący stany procesu:
/* Used in tsk->state: */
#define TASK_RUNNING 0x0000
#define TASK_INTERRUPTIBLE 0x0001
#define TASK_UNINTERRUPTIBLE 0x0002
#define __TASK_STOPPED 0x0004
#define __TASK_TRACED 0x0008
/* Used in tsk->exit_state: */
#define EXIT_DEAD 0x0010
#define EXIT_ZOMBIE 0x0020
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* Used in tsk->state again: */
#define TASK_PARKED 0x0040
#define TASK_DEAD 0x0080
#define TASK_WAKEKILL 0x0100
#define TASK_WAKING 0x0200
#define TASK_NOLOAD 0x0400
#define TASK_NEW 0x0800
#define TASK_STATE_MAX 0x1000
/* Convenience macros for the sake of set_current_state: */
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
#define TASK_IDLE (TASK_UNINTERRUPTIBLE | TASK_NOLOAD)
/* Convenience macros for the sake of wake_up(): */
#define TASK_NORMAL (TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE)
/* get_task_state(): */
#define TASK_REPORT (TASK_RUNNING | TASK_INTERRUPTIBLE | \
TASK_UNINTERRUPTIBLE | __TASK_STOPPED | \
__TASK_TRACED | EXIT_DEAD | EXIT_ZOMBIE | \
TASK_PARKED)
Do najważniejszych stanów procesów należą te, które jądro pozwala nam łatwo odczytywać przy pomocy funkcji const char *get_task_state, która przypisuje stan do zmiennej znakowej (ang. char) zawartej w tablicy task_state_array.
static const char * const task_state_array[] = {
/* states in TASK_REPORT: */
"R (running)", /* 0x00 */
"S (sleeping)", /* 0x01 */
"D (disk sleep)", /* 0x02 */
"T (stopped)", /* 0x04 */
"t (tracing stop)", /* 0x08 */
"X (dead)", /* 0x10 */
"Z (zombie)", /* 0x20 */
"P (parked)", /* 0x40 */
/* states beyond TASK_REPORT: */
"I (idle)", /* 0x80 */
};
static inline const char *get_task_state(struct task_struct *tsk)
{
BUILD_BUG_ON(1 + ilog2(TASK_REPORT_MAX) != ARRAY_SIZE(task_state_array));
return task_state_array[task_state_index(tsk)];
}Znając już stany procesów na poziomie jądra (warto zwrócić uwagę na specjalny dobór ich wartości i możliwość przeprowadzania na nich operacjach bitowych) możemy przejść dalej i omówić, czym jest loadavg.
Load average – definicja
Zgodnie z manualem man 5 proc loadavg zawiera w sobie statystykę będącą średnią sumującą procesy w stanach R i D. Oznacza to, że mamy tutaj procesy:
- oczekujące w kolejce do wykonania (Stan R)
- wykonywane (Stan R)
- śpiące w stanie D – czekające na I/O dysk.
Większość opracowań w internecie nie ujmuje faktu, iż stan R może oznaczać zarówno wykonywanie, jak i oczekiwanie w kolejce na bycie wykonanym. Często mylone są też pojęcia stanu czekającego na uruchomienie (stan R) z oczekującym na I/O (stan D). Na dodatek nie zwraca się uwagi na to, iż w przypadku wysycenia pamięci RAM i użycia pamięci rozszerzonej (ang. swap) procesy także wpadają w stan D.
Load average podawany jest dla 3 okresów:
- ostatniej minuty
- ostatnich 5 minut
- ostatnich 15 minut.
Pozwala to administratorowi na zrozumienie trendu obciążenia systemu.
Średnie obciążenie systemu (load average) powinno być rozpatrywane w kontekście ilości dostępnych CPU z uwzględnieniem mechanizmów SMT (Simultaneous MultiThreading) i HT (Hyper-Threading). Najłatwiejszym sposobem, by znaleźć ilość dostępnych procesorów (w znaczeniu procesora logicznego), jest użycie komendy nproc.
Przykładowe wywołanie komendy uptime (zwracającej między innymi load average) oraz nproc:
[Alex@NormandyV2 loadavg]$ uptime
17:22:55 up 5:37, 5 users, load average: 4.92, 4.89, 4.84
[Alex@NormandyV2 loadavg]$ nproc
8Najprostszą zasadą dotyczącą load average jest to, że powinien być on mniejszy od dostępnych jednostek obliczeniowych. Oczywiście w zależności od rzeczywistego użycia poszczególnych zasobów, system i jego usługi mogą wcale nie działać satysfakcjonująco. Patrząc na powyższy przykład, w przypadku 8 procesorów logicznych i loadavg na poziomie około 5 system nie jest przeciążony. Jednak gdy ilość procesorów byłaby mniejsza niż 5, to mielibyśmy do czynienia z potencjalnie przeciążonym systemem.
Interfejs plikowy /proc/loadavg
Pod ścieżką /proc/loadavg jądro Linux udostępnia interfejs plikowy z informacjami dotyczącymi średniego obciążenia systemu. Korzystają z niego miedzy innymi takie programy jak uptime, w czy top.
[Alex@SpaceStation ~]$ strace w |& grep loadavg
read(6, "grep\0--color=auto\0loadavg\0", 2047) = 26
openat(AT_FDCWD, "/proc/loadavg", O_RDONLY) = 6
[Alex@SpaceStation ~]$ strace uptime |& grep loadavg
openat(AT_FDCWD, "/proc/loadavg", O_RDONLY) = Plik /proc/loadvg zwraca następujące wartości (zapis pseudokodowy):
LOAD_AVG_1_MIN LOAD_AVG_5_MIN LOAD_AVG_15_MIN NUMBER_OF_RUNNING/NUMBER_OF_THREADS LAST_CREATED_PID
Przykładowy odczyt pliku /proc/loadavg
[Alex@NormandySR2 ~]$ cat /proc/loadavg 5.93 2.14 1.67 17/1396 173294
Jeśli chodzi zaś o plik źródłowy definiujący ten interfejs, jest to linux/fs/proc/loadavg.c. Pozwolę sobie zamieścić fragment kodu, gdyż uważam go za bardzo dobry przykład tego, że kod jądra potrafi być fascynujący:
static int loadavg_proc_show(struct seq_file *m, void *v)
{
unsigned long avnrun[3];
get_avenrun(avnrun, FIXED_1/200, 0);
seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d\n",
LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]),
LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]),
LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]),
nr_running(), nr_threads,
idr_get_cursor(&task_active_pid_ns(current)->idr) - 1);
return 0;
}Chciałbym tutaj zwrócić uwagę na nieoczywiste techniki użyte w tak krótkim fragmencie kodu.
- Po pierwsze na uwagę zasługuje użycie zmiennej typu
unsigned long, a następnie bardzo specyficzne rzutowanie jej na część całkowitą przez makroLOAD_INToraz ułamek przez makroLOAD_FRAC. Wśród większości programistów języków wysokiego poziomu rozwiązanie to budzi pewne zażenowanie. Jednak w przypadku programowania jądra, gdzie efektywność kodu ma kluczowe znaczenie, tego typu „haksy” (od ang. hack w znaczeniu wyjątkowo sprytnego rozwiązania – http://www.catb.org/jargon/html/H/hack.html) są wyjątkowo pożądane. - Warto też zwrócić uwagę na zmienną
nr_threads, która jest zmienną informującą o ilości zadań w systemie oraz na funkcję nr_running(), która ma za zadanie zwrócić tylko zadania będące w stanie R.
Pobranie load average przy pomocy wywołania systemowego
By pobrać loadavg możemy użyć wywołania systemowego sysinfo. Zwraca ono strukturę sysinfo, która wygląda następująco:
struct sysinfo {
long uptime; /* Seconds since boot */
unsigned long loads[3]; /* 1, 5, and 15 minute load averages */
unsigned long totalram; /* Total usable main memory size */
unsigned long freeram; /* Available memory size */
unsigned long sharedram; /* Amount of shared memory */
unsigned long bufferram; /* Memory used by buffers */
unsigned long totalswap; /* Total swap space size */
unsigned long freeswap; /* Swap space still available */
unsigned short procs; /* Number of current processes */
char _f[22]; /* Pads structure to 64 bytes */
};Jeżeli chcemy sami stworzyć program, który sczytuje loadavg bez wykorzystania interfejsu plikowego (omawianego wcześniej /proc/loadavg), powyższe wywołanie systemowe jest najprostszym sposobem do zebrania informacji o stanie systemu. Przykładowy prosty raport w języku C:
#include <linux/kernel.h>
#include <stdio.h>
#include <sys/sysinfo.h>
int main ()
{
// consts
const double mb=1024*1024;
const float load_avg_sysinfo_scale = 2<<16; // this is magic number
// get sysinfo structure
struct sysinfo s;
sysinfo (&s);
// print raport
printf ("--- Raport systemowy ---\n");
printf ("Load AVG: 1min[%4.2f] 5min[%4.2f] 15min[%4.2f]\n",
s.loads[0]/load_avg_sysinfo_scale,
s.loads[1]/load_avg_sysinfo_scale,
s.loads[2]/load_avg_sysinfo_scale);
printf ("Calkowita pamięć RAM: %8.2f MB\n", s.totalram / mb);
printf ("Wolna (nieuzywana) pamięć RAM: %8.2f MB\n", s.freeram / mb);
printf ("Calkowita pamiec rozszerzona (swap): %8.2f MB\n", s.totalswap / mb);
printf ("Wolna pamiec rozszerzona (swap): %8.2f MB\n", s.freeswap / mb);
printf ("Ilosc procesow w systemie: %d\n", s.procs);
return 0;
}oraz jego kompilacja wraz z uruchomieniem:
[Alex@NormandySR2 loadavg]$ gcc -Wpedantic raport_systemowy.c -o raport_systemowy && ./raport_systemowy
--- Raport systemowy ---
Load AVG: 1min[0.32] 5min[0.22] 15min[0.18]
Całkowita pamięć RAM: 31871.28 MB
Wolna (nieuzywana) pamięć RAM: 22587.86 MB
Całkowita pamiec rozszerzona (swap): 20095.99 MB
Wolna pamiec rozszerzona (swap): 20095.99 MB
Ilość procesów w systemie: 1470
[Alex@NormandySR2 loadavg]$ Mity związane z load average
Mit 0 – load average to ilości procesów właśnie działających w systemie/na CPU
Jest to najczęściej popełniany błąd (wynikający z braków wiedzy o stanach procesów), jaki słyszę podczas rozmów rekrutacyjnych. Jak już wielokrotnie wyżej podkreślaliśmy, load average zawiera w sobie zarówno procesy w stanie R (uruchomione i gotowe do uruchomienia), jak i D (oczekujące). Jeśli load average określałby tylko to, ile procesów jest uruchomionych, nigdy nie byłby większy niż ilość jednostek obliczeniowych w systemie. Powyższa odpowiedź kandydata szybko doprowadza do sprzeczności.
Mit 1 – load average jest średnią arytmetyczną
Jest to jedno z trudniejszych pytań, które są tzw. „follow up questions” (dalszymi pytaniami podczas rekrutacji, często mającymi sprawdzić, jak głęboka jest wiedza na zadany temat u kandydata).
W manualu man 5 proc jest napisane:
/proc/loadavg
The first three fields in this file are load average figures
giving the number of jobs in the run queue (state R) or waiting for disk I/O
(state D) averaged over 1, 5, and 15 minutes.(...)
Warto tutaj zajrzeć do polskiej wersji tłumaczenia strony man 5 proc stworzonej przez autorów: Przemek Borys, Robert Luberda oraz Michał Kułacha:
/proc/loadavg
Pierwsze trzy pola w tym pliku zawierają średnie obciążenie (loadavg) podając
informację o średniej liczbie zadań uruchomionych (stan R) oraz czekających na
dyskowe operacje wejścia/wyjścia (stan D) w ciągu ostatnich 1, 5 i 15 minut.(...)Mogłoby się wydawać w takim razie, że mamy tutaj do czynienia ze zwykłą średnią arytmetyczną. Ostateczną odpowiedź dadzą zatem źródła Linuksa, które wprost opisują load average jako:
/*
* ...
* The global load average is an exponentially decaying average of nr_running +
* nr_uninterruptible.
* ...
*/Mamy więc do czynienia z wykładniczą średnią ruchomą, w której dalsze próby mają mniejszy wpływ na wynik niż próby nowsze.
Mit 2 – wysoki load average jest zawsze powiązany z procesorem
Jak już wcześniej zostało wytłumaczone, loadavg zlicza w wykładniczej średniej ruchomej procesy w stanie R i D. Oznacza to, że procesy te mogą:
- czekać na CPU (R)
- wykonywać się na CPU (R)
- czekać na dysk (D)
- czekać na wczytanie stron pamięci z dysku (D).
Mamy więc co najmniej trzy komponenty, które mogą być przeciążone:
- CPU
- dysk
- pamięć RAM (wyczerpanie i konieczność użycia swap).
Możliwości jest zatem kilka i mogą wystąpić zarówno pojedynczo, w parach, jak i wszystkie naraz.
Na dodatek może się zdarzyć, iż wysoki loadavg nie oznacza wcale zbytniego przeciążenia systemu. Przykładowo obciążenie procesora na poziomie połowy jego możliwości + swapowanie (wysycenie RAM-u wraz z koniecznością zrzucania i wczytywania stron pamięci na/z dysku) może skutkować wysokim loadavg.
Średnie obciążenie jest więc statystyką, która w dużej mierze zwraca uwagę na konieczność dalszych kroków diagnostycznych w celu zrozumienia stanu systemu i jego procesów.
Mit 3 – load average ma głęboki sens
Jako ciekawostkę z pograniczna informatyki i filozofii chciałbym przytoczyć komentarz zawarty w źródłach Linuksa w pliku linux/sched/loadavg.c.
/*
* kernel/sched/loadavg.c
*
* This file contains the magic bits required to compute the global loadavg
* figure. Its a silly number but people think its important. We go through
* great pains to make it work on big machines and tickless kernels.
*/W swobodnym tłumaczeniu oznacza to:
/*
* kernel/sched/loadavg.c
*
* Plik ten zawiera w sobie magiczne bity potrzebne do wyliczenia całkowitego
* loadavg. Jest to śmieszna liczba ale ludzie sądzą że jest ważna. Wiele
* trudu kosztowało nas by wyliczenia te działały na dużych maszynach i
* jądrach z swobodną obsługą przerwań.
*/Niestety w języku polskim nie istnieje standaryzowane tłumaczenie tickless kernel. Niemniej chodzi tutaj o fakt, iż jądro Linux potrafi tak zarządzać procesorem, by przerwania systemowe nie występowały w stałych odstępach (stąd nazwa ang. tick od tykania, np. co 1000 Hz [cykli procesora] i less [od angielskiego „bez”]) lecz były ustawiane dynamicznie. Stąd moje autorskie tłumaczenie (jądra ze swobodną obsługą przerwań).
Mówiąc szczerze, gdy pierwszy raz w moim życiu zobaczyłem ten komentarz, oniemiałem. Przecież mowa o jednej z najważniejszych z punktu widzenia administratora statystyk w systemie! Zastanawiając się zatem i czytając pliki źródłowe, chciałbym zwrócić uwagę, że z punktu widzenia programisty jądra, statystyka ta nie jest wcale oczywista i „pewna” (w znaczeniu zaufania do niej) z wielu względów:
- procesory dynamicznie skalują swoje osiągi ze względu na wiele czynników, w tym między innymi obciążenie i temperaturę
- by dokładnie ją wyliczyć, należałoby co zadany fragment czasu de facto zamrozić system, przynajmniej podczas odczytu wartości loadavg (mówi o tym zresztą inny komentarz w tym pliku “These values are estimates at best, so no need for locking.”, co można przetłumaczyć jako „Te wartości w najlepszym wypadku są szacunkowe, nie ma więc potrzeby na użycie blokady”
- w przypadku maszyn wieloprocesorowych, a także jąder ze swobodną obsługą przerwań, obliczenia są jeszcze bardziej szacunkowe.
Powstaje zatem naturalne pytanie – czy load average ma sens? No cóż, można by pokusić się o stwierdzenie, że skoro sami autorzy powątpiewają, to może nie do końca. Niemniej jeśli nawet na eksperckim poziomie wiedzy i zrozumienia skomplikowania widzimy wady rozwiązania, ale w ogólnym rozrachunku ono działa, to warto tutaj jednak zastosować prawo Murphy’ego: „If it’s stupid but it works, it isn’t stupid.”, czyli „Jeśli jest głupie, ale działa, to nie jest głupie”. Jak mówiłem na wstępie, proszę potraktować powyższy wywód w kategoriach luźnych rozważań skromnego autora.
Podsumowanie
W artykule omówiono stany, w jakich może znajdować się proces, w jaki sposób od środka (tj. w źródłach jądra Linux) wygląda load average oraz jak, jako administratorzy i programiści możemy dostać się do tej wartości. Na koniec rozprawiliśmy się z powszechnymi mitami dotyczącymi tej przydatnej statystyki.
Bibliografia
https://elixir.bootlin.com/linux/v5.9.3/source/include/linux/sched.h#L69
https://elixir.bootlin.com/linux/v5.9.3/source/fs/proc/array.c#L129
https://elixir.bootlin.com/linux/v5.9.3/source/fs/proc/loadavg.c
http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html – artykuł wybitnego specjalisty w dziedzinie badania wydajności i dostrajania systemów Linux – Brendana Gregga
man 5 proc
man 2 sysinfo