
 2020-06-29
2020-06-29
Krótkie omówienie procesu kompilacji w systemie Linux z GCC
Materiał ten powstał w celu przedstawienia podstawowego procesu kompilacji w systemie Linux. Omówiłem w nim główne kroki wykonywane przez kompilator w celu zamiany kodu źródłowego w kod maszynowy. Zawiera on także krótkie przykłady pozwalające na zrozumienie procesu kompilacji przy użyciu kompilatora GCC.
Materiał ten powstał w celu przedstawienia podstawowego procesu kompilacji w systemie Linux. Omówiłem w nim główne kroki wykonywane przez kompilator w celu zamiany kodu źródłowego w kod maszynowy. Zawiera on także krótkie przykłady pozwalające na zrozumienie procesu kompilacji przy użyciu kompilatora GCC.
Na początku stwórzmy przykładową hierarchię folderów i program:
mkdir -pv ~/workspace/c-tmp cd ~/workspace/c-tmp
Następnie wpiszmy kod programu do pliku hello.c:
#include <stdio.h>
#include "hello2.c"
void print_hello(){
printf("Hello, World!\n");
}
int main(){
print_hello();
print_pi();
return 0;
}
Kod programu znajdujący się w pliku hello2.c:
#include <stdio.h>
#define PI 3.14159
void print_pi(){
printf("PI ~= %f\n", PI);
}
By nie przepisywać kodu, proponuję użyć gistów z githuba:
wget https://gist.githubusercontent.com/AlexBaranowski/4a3e04cb707df9a1a0935d0a180bd1fa/raw/9fc4b8251f9ea7ee6aa21ebb645470ba1ebaac1c/hello.c wget https://gist.githubusercontent.com/AlexBaranowski/4a3e04cb707df9a1a0935d0a180bd1fa/raw/9fc4b8251f9ea7ee6aa21ebb645470ba1ebaac1c/hello2.c
Mając taki kod możemy go od razu skompilować w następujący sposób:
gcc hello.c -o myhelloworld.out
Następnie uruchamiamy:
./myhelloworld.out Hello, World! PI ~= 3.141590
Kompilowanie krok po kroku
Podstawowy proces kompilowania programu napisanego w języku C przebiega według następujących faz:
1. Faza pierwsza: wykonywany jest program preprocesora.
2. Faza druga: kompilacja z kodu do assemblera.
3. Faza trzecia: kompilacja z assemblera do kodu maszynowego.
4. Faza czwarta: łączenie programu przy pomocy linkera.
Poniżej schemat ogólnego procesu kompilacji.
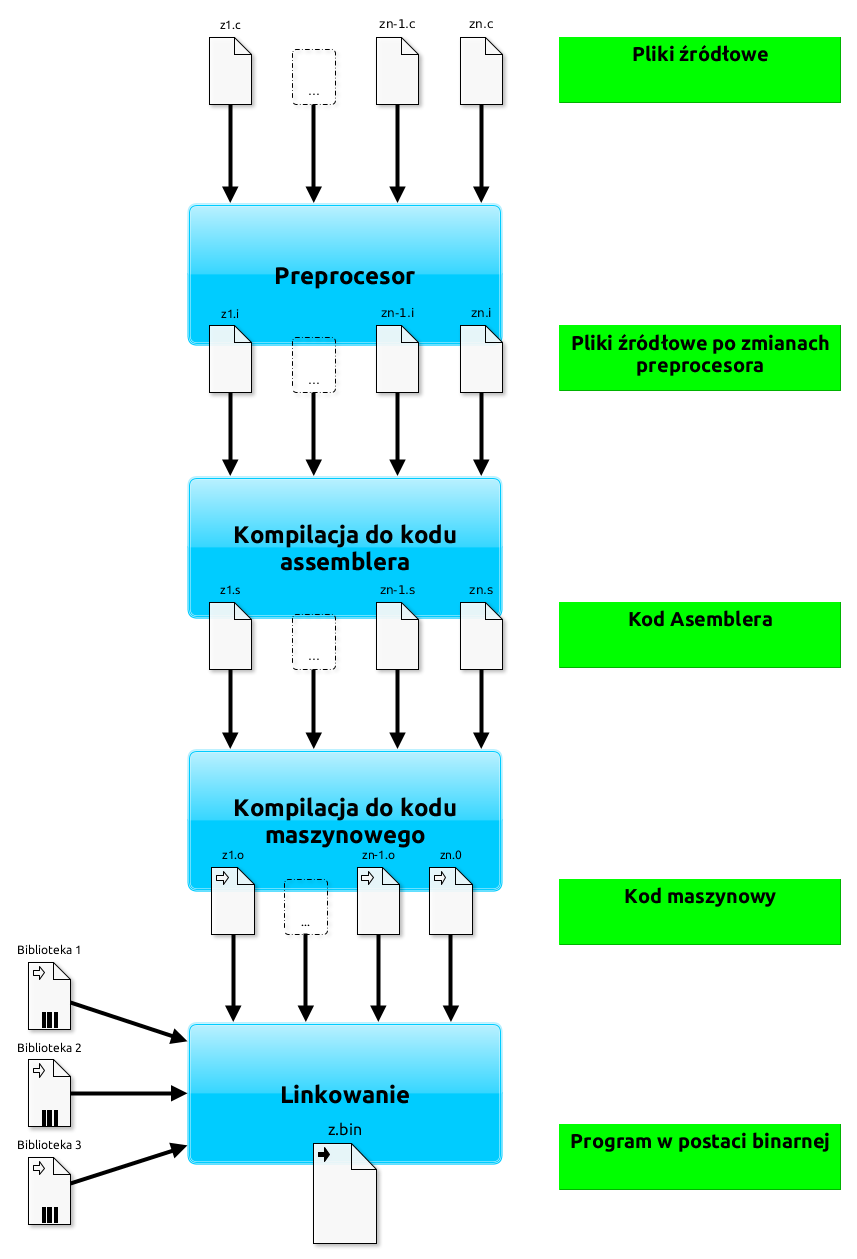
Faza wykonania preprocesora
W fazie tej makra preprocesora są rozwijane. Preprocesor jest stosunkowo prostym programem, który posiada zbiór dyrektyw warunkujących jego zachowanie. Makra preproceosra zaczynają się od #. W przykładzie mamy makra #include<>, #include'' oraz stworzone przez nas makro #define PI 3.14159. Program preprocesora nosi nazwę cpp, od C preprocesor. Jest on wykonywany właśnie przez kompilator gcc przed fazą kompilacji. W celu zakończenia kompilacji na fazie preprocesora należy użyć opcji -E.
Użyjmy gcc do preprocesowania pliku hello.c z przekierowaniem do pliku hello.c.preprocessed_gcc:
[Alex@Normandy omowienie_kompilacji]$ gcc -E hello.c > hello.c.preprocessed_gcc
Użyjmy samego cpp do preprocesowania pliku hello.c z przekierowaniem do pliku hello.c.preprocessed_cpp:
[Alex@Normandy omowienie_kompilacji]$ cpp hello.c > hello.c.preprocessed_cpp
Następnie możemy porównać obydwa pliki. Użyłem programu wc, by pokazać, że pliki nie są puste:
[Alex@Normandy omowienie_kompilacji]$ wc hello.c.preprocessed_gcc hello.c.preprocessed_cpp 853 2095 17026 hello.c.preprocessed_gcc 853 2095 17026 hello.c.preprocessed_cpp 1706 4190 34052 total [Alex@Normandy omowienie_kompilacji]$ diff hello.c.preprocessed_gcc hello.c.preprocessed_cpp [Alex@Normandy omowienie_kompilacji]$ sha1sum hello.c.preprocessed_gcc hello.c.preprocessed_cpp c3804917869778d425569797d7051c6f289c7b8d hello.c.preprocessed_gcc c3804917869778d425569797d7051c6f289c7b8d hello.c.preprocessed_cpp
Wiedząc już, że w tym kroku gcc pod spodem wykonuje cpp, możemy przejść dalej.
Faza kompilacji do assemblera
Faza ta dostaje preprocesowany kod i generuje kod assemblera. Co istotne, w kroku tym występuje optymalizacja, co zaraz pokażemy przy pomocy kolejnego przykładu. Bardzo ważną rolę pełnią tutaj pośrednie formaty zapisu kodu, o których przeczytacie w kolejnym artykule.
By zatrzymać kompilację programu na fazie wygenerowania kodu assemblera, należy użyć opcji -S. Dostajemy w ten sposób plik hello.s. Użyjemy także opcji -x, by poinformować gcc, od której fazy ma zacząć swoją pracę.
[Alex@Normandy omowienie_kompilacji]$ gcc -S -x cpp-output hello.c.preprocessed_cpp
Możemy teraz przeczytać kod assemblera:
[Alex@Normandy omowienie_kompilacji]$ cat hello.c.s .file "hello.c" .section .rodata .LC1: .string "PI ~= %f\n" .text .globl print_pi .type print_pi, @function print_pi: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $16, %rsp movabsq $4614256650576692846, %rax movq %rax, -8(%rbp) movsd -8(%rbp), %xmm0 movl $.LC1, %edi movl $1, %eax call printf leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size print_pi, .-print_pi .section .rodata .LC2: .string "Hello, World!" .text .globl print_hello .type print_hello, @function print_hello: .LFB1: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $.LC2, %edi call puts popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE1: .size print_hello, .-print_hello .globl main .type main, @function main: .LFB2: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $0, %eax call print_hello movl $0, %eax call print_pi movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE2: .size main, .-main .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-39)" .section .note.GNU-stack,"",@progbits
Właśnie na tym etapie następuje, przynajmniej częściowo, optymalizacja. Stwórzmy prosty program z dwiema pustymi pętlami. W moim przypadku nazywa się on empty.c.
#include<stdio.h>
int main(){
int i, j;
for (i=0; i < 100000;i++){
for (j=0; j < 100000;j++){
}
}
printf("Finish!");
}
wget https://gist.githubusercontent.com/AlexBaranowski/742bfee08c9b4b924157e984d8092624/raw/213d2f7ee7c0687bd0c240db5c091d862204b913/empty.c
[Alex@Normandy omowienie_kompilacji]$ gcc -O0 empty.c -o empty_0 [Alex@Normandy omowienie_kompilacji]$ gcc -O3 empty.c -o empty_3
[Alex@Normandy omowienie_kompilacji]$ time ./empty_0 ; time ./empty_3 Finish! real 0m19.078s user 0m19.072s sys 0m0.002s Finish! real 0m0.001s user 0m0.000s sys 0m0.001s
[Alex@Normandy omowienie_kompilacji]$ gcc -S -O0 empty.c -o empty_0.s [Alex@Normandy omowienie_kompilacji]$ gcc -S -O3 empty.c -o empty_3.s
[Alex@Normandy omowienie_kompilacji]$ diff -y empty_0.s empty_3.s .file "empty.c" .file "empty.c" .section .rodata | .section .rodata.str1.1,"aMS",@progbits,1 .LC0: .LC0: .string "Finish!" .string "Finish!" .text | .section .text.startup,"ax",@progbits > .p2align 4,,15 .globl main .globl main .type main, @function .type main, @function main: main: .LFB0: | .LFB11: .cfi_startproc .cfi_startproc pushq %rbp < .cfi_def_cfa_offset 16 < .cfi_offset 6, -16 < movq %rsp, %rbp < .cfi_def_cfa_register 6 < subq $16, %rsp < movl $0, -4(%rbp) < jmp .L2 < .L5: < movl $0, -8(%rbp) < jmp .L3 < .L4: < addl $1, -8(%rbp) < .L3: < cmpl $99999, -8(%rbp) < jle .L4 < addl $1, -4(%rbp) < .L2: < cmpl $99999, -4(%rbp) < jle .L5 < movl $.LC0, %edi movl $.LC0, %edi movl $0, %eax | xorl %eax, %eax call printf | jmp printf leave < .cfi_def_cfa 7, 8 < ret < .cfi_endproc .cfi_endproc .LFE0: | .LFE11: .size main, .-main .size main, .-main .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-39) .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-39) .section .note.GNU-stack,"",@progbits .section .note.GNU-stack,"",@progbits
W celu zwiększenia czytelności pozwolę sobie wkleić zoptymalizowany kod:
[Alex@Normandy omowienie_kompilacji]$ cat empty_3.s .file "empty.c" .section .rodata.str1.1,"aMS",@progbits,1 .LC0: .string "Finish!" .section .text.startup,"ax",@progbits .p2align 4,,15 .globl main .type main, @function main: .LFB11: .cfi_startproc movl $.LC0, %edi xorl %eax, %eax jmp printf .cfi_endproc .LFE11: .size main, .-main .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-39)" .section .note.GNU-stack,"",@progbits
Nawet bez głębszej znajomości assemblera widać, że nie występuje tutaj pętla. Oznacza to, iż program został zoptymalizowany w tej fazie.
Faza kompilacji z assemblera do kodu maszynowego
Faza ta również nie jest realizowana przez kompilator gcc. Wykorzystuje ona kompilator języka asembler as będący częścią pakietu binutils, czyli podstawowych narzędzi do obsługi plików binarnych.
Przykładowa kompilacja do „pliku obiektu” (ang. object file). Plik taki nie jest uruchamialny, ale jest między innymi linkowalny:
[Alex@Normandy omowienie_kompilacji]$ as hello.c.s -o hello_as.o
Ta sama kompilacja z assemblera do pliku obiektu z pomocą gcc, ale tym razem z użyciem opcji -c w celu przerwania procesu kompilacji na etapie generowania pliku obiektu. Dodatkowo użyliśmy opcji -x assembler, by rozpocząć kompilację od poprzedniego etapu:
[Alex@Normandy omowienie_kompilacji]$ gcc hello.c.s -c -x assembler -o hello_gcc.o
Następnie możemy, przy pomocy sumy pliku wyliczonej z wykorzystaniem algorytmu mieszającego, sprawdzić, czy pliki są jeden do jednego takie same:
[Alex@Normandy omowienie_kompilacji]$ sha1sum hello_gcc.o hello_as.o b753888d5654e73f5902b6591c81740e05fd90f9 hello_gcc.o b753888d5654e73f5902b6591c81740e05fd90f9 hello_as.o
Faza linkowania
Za linkowanie ponownie odpowiada zewnętrzne narzędzie ld, czyli linker. Linker łączy ze sobą wiele plików obiektów. Zmienia ich przestrzenie adresowe, łączy odpowiednie fragmenty programu itd. Jego wyjściem może być między innymi plik uruchamialny (tzw. binarka) lub plik współdzielony (inaczej biblioteka współdzielona/obiekt współdzielony).
By wykonać tylko fazę linkowania, można uruchomić gcc z następującymi parametrami:
[Alex@Normandy omowienie_kompilacji]$ gcc hello_gcc.o -o hello_gcc Hello, World! PI ~= 3.141590
By ręcznie stworzyć uruchamialny plik binarny, trzeba się niestety nieco bardziej napracować. Ponieważ używamy formatu ELF, powinniśmy na początku i końcu umieścić specjalny kod, który jest wykonywany zarówno przed, jak i po wykonaniu programu. Nie wchodząc w szczegóły, przykładowe wywołanie ld będzie następujące:
[Alex@Normandy omowienie_kompilacji]$ ld --build-id --no-add-needed --eh-frame-hdr \ --hash-style=gnu -m elf_x86_64 -dynamic-linker /lib64/ld-linux-x86-64.so.2 \ -o hello_ld /lib64/crt1.o /lib64/crti.o /lib/gcc/x86_64-redhat-linux/4.8.5/crtbegin.o \ -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5 -L/lib64 ./hello_gcc.o -lgcc --as-needed -lgcc_s \ --no-as-needed -lc -lgcc --no-as-needed /lib/gcc/x86_64-redhat-linux/4.8.5/crtend.o \ /lib64/crtn.o [Alex@Normandy omowienie_kompilacji]$ ./hello_ld Hello, World! PI ~= 3.141590
Po takim wywołaniu obydwa pliki będą identyczne:
[Alex@Normandy omowienie_kompilacji]$ file ./hello_{ld,gcc}
./hello_ld: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=6da375433eff9e0005f79c610f7b30ad93b9d0db, not stripped
./hello_gcc: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=6da375433eff9e0005f79c610f7b30ad93b9d0db, not stripped
[Alex@Normandy omowienie_kompilacji]$ sha1sum ./hello_{ld,gcc}
58678ae2f5b63b3f1da630a1499998e10c3dba51 ./hello_ld
58678ae2f5b63b3f1da630a1499998e10c3dba51 ./hello_gcc
Bez wątpienia jest to dość skomplikowany proces. Jeśli jesteście zainteresowani tym, co oznaczają poszczególne przełączniki, zachęcam do przestudiowania podręcznika systemowego ld (man 1 ld). Chciałbym jednak zaznaczyć, że zrozumienie tego tematu wymaga znajomości formatu ELF, o którym między innymi będzie następny artykuł.
Kompilowanie statyczne z gcc
By skompilować zadany program, statycznie należy użyć przełącznika -static. W tym wypadku odpowiedni kod bibliotek zostanie zamieszczony wraz z plikiem binarnym.
Przed skompilowaniem statycznym należy jednak zainstalować pakiety dostarczające biblioteki w wersji statycznej:
[Alex@Normandy omowienie_kompilacji]$ sudo yum install -y glib2-static glibc-static
Po tym zabiegu możemy skompilować nasz program do binarki niewymagającej dodatkowych bibliotek:
[Alex@Normandy omowienie_kompilacji]$ gcc hello.c -static -o hello_static [Alex@Normandy omowienie_kompilacji]$ file hello_ld hello_static hello_ld: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=6da375433eff9e0005f79c610f7b30ad93b9d0db, not stripped hello_static: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, for GNU/Linux 2.6.32, BuildID[sha1]=b1831ba701348398828a89c8209da87575e8a11d, not stripped
Na sam koniec warto zauważyć, że ponieważ program został ponownie skompilowany przez co zmienił się BuildID.
Zakończenie
Zdaję sobie sprawę z tego, że materiał ten porusza bardzo obszerny temat. Sam podręcznik GCC (ang. manual) ma bowiem ponad 1000 stron. Należy do tego dodać konieczność znania szerszego kontekstu oraz minimalne umiejętności programistyczne. W przyszłym miesiącu na naszym blogu pojawi się tekst obejmujący między innymi różne formaty zapisu plików wykonywalnych i bibliotek. Następnie omówimy wewnętrzny sposób działania dwóch najpopularniejszych kompilatorów – gcc i llvm.