We prepared the broadest overlook on the changes and new functionalities. PostgreSQL is an object-relational database management system, developed at the University of California at Berkeley Computer Science Department. With over two decades of development behind it, PostgreSQL is now the most advanced open-source database available anywhere.
On September 30, 2021 the latest version of PostgreSQL 14 was released! Postgres fans had the opportunity to celebrate the whole week, because 6 days earlier was the first anniversary of version 13. It is therefore a great time to look at the changes that the creators of the top database engine have prepared in the current version. In a word of introduction, let’s first explain what Postgres is and what it means in the current market.
PostgreSQL is an object-relational database management system, developed at the University of California at Berkeley Computer Science Department. With over two decades of development behind it, PostgreSQL is now the most advanced open-source database available anywhere.
History of Postgres
The POSTGRES project, led by Professor Michael Stonebraker, was sponsored among others by the Defense Advanced Research Projects Agency (DARPA). The implementation of POSTGRES began in 1986 and first demo version was operational in 1987.
In 1994, Andrew Yu and Jolly Chen added an SQL language interpreter to POSTGRES. Under a new name, Postgres95 was released to the web as an open-source descendant of the original POSTGRES Berkeley code. Interestingly Postgres95 code was completely ANSI C, trimmed in size by 25% and ran about 30–50% faster compared to POSTGRES.
By 1996, it became clear that the name “Postgres95” would not stand the test of time. So they chose a new name, PostgreSQL, to reflect the relationship between the original POSTGRES and the more recent versions with SQL capability. Worth noting is that they set the version numbering to start at 6.0, putting the numbers back into the sequence originally begun by the Berkeley POSTGRES project.
Postgres, or PostgreSQL?
Many people continue to refer to PostgreSQL as “Postgres” (now rarely in all capital letters) because of tradition or because it is easier to pronounce. This usage is widely accepted as a nickname or alias.
Popularity of Postgres
According to Google Trends, the popularity of PostgreSQL (blue) continues to increase, and its advantage between paid solutions such as Oracle (red) has started to increase dramatically. This happened throughout 2015, when new solutions such as MongoDB (yellow) became more popular.
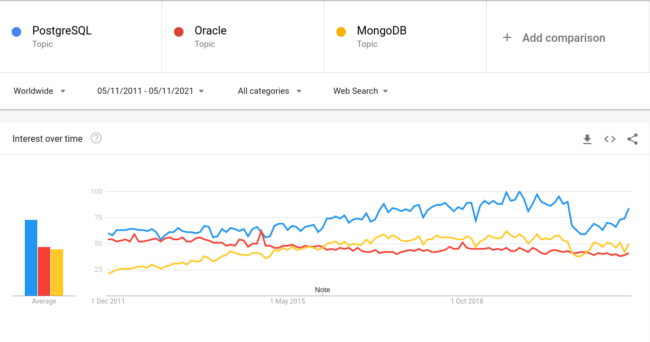 The graph shows interest over time – the peak of popularity of a topic in Google searches was marked as 100. A value of 50 means that the topic was half as popular.
The graph shows interest over time – the peak of popularity of a topic in Google searches was marked as 100. A value of 50 means that the topic was half as popular.
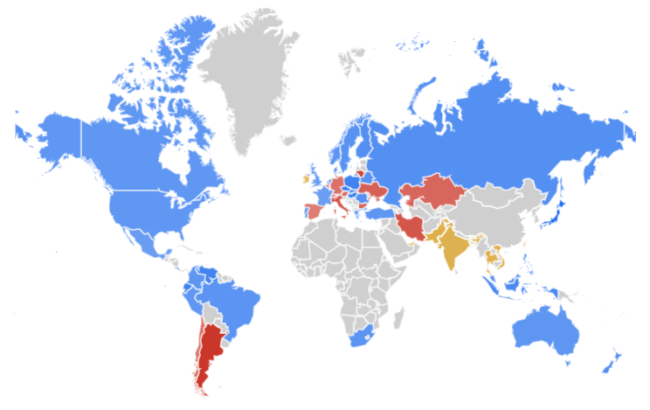
The map shows the popularity of PostgreSQL (blue), Oracle (red), MongoDB (yellow) over the last 10 years. The darker the color, the greater its advantage in a given region. Gray color means no data.
PostgreSQL 14 compared to PostgreSQL 13
Version 14 of the PostgreSQL relational database was released on September 30, 2021 and has a number of new features compared to its predecessor. The creators of the latest version of Postgres noticeably focused on database performance, a new replication method, or emergency mode for garbage-collector. These are only examples of new features that can be found in the latest version of PostgreSQL 14. A comprehensive list of all changes is available below.
Detailed list of new functionalities and changes in PostgreSQL 14
The list has been divided into the following categories: Server, Streaming Replication and Recovery, SELECT, INSERT, Utility Commands, Data types, Functions, PL/PgSQL, Client Interfaces, Client Applications, Server Applications, Documentation, Source Code, Additional Modules. The list below describes any changes between PostgreSQL 14 and the previous major Postgres release.
Server
| Change |
Additional informations |
Author(s) |
| Add predefined roles pg_read_all_data and pg_write_all_data |
These non-login roles can be used to give read or write permission to all tables, views, and sequences |
Stephen Frost |
| Add predefined role pg_database_owner that contains only the current database’s owner |
This is especially useful in template databases |
Noah Misch |
| Remove temporary files after backend crashes |
Previously, such files were retained for debugging purposes. If necessary, deletion can be disabled with the new server parameter remove_temp_files_after_crash |
Euler Taveira |
| Allow long-running queries to be canceled if the client disconnects |
The server parameter client_connection_check_interval allows control over whether loss of connection is checked for intra-query (this is supported on Linux and a few other operating systems) |
Sergey Cherkashin, Thomas Munro |
| Add an optional timeout parameter to pg_terminate_backen |
– |
– |
| Allow wide tuples to be always added to almost-empty heap pages |
Previously tuples whose insertion would have exceeded the page’s fill factor were instead added to new pages |
John Naylor, Floris van Ne |
| Add Server Name Indication (SNI) in SSL connection packets |
This can be disabled by turning off client connection option sslsni |
Peter Eisentraut |
Server – vacuuming
Vacuum is another name for Garbage-Collector, in other words a tool for collecting and removing unnecessary things (so-called garbage) from the database – e.g. dead tuples.
| Change |
Additional informations |
Author(s) |
| Allow vacuum to skip index vacuuming when the number of removable index entries is insignificant |
The vacuum parameter INDEX_CLEANUP has a new default of auto that enables this optimization |
Masahiko Sawada, Peter Geoghegan |
| Allow vacuum to more eagerly add deleted btree pages to the free space map |
Previously vacuum could only add pages to the free space map that were marked as deleted by previous vacuums |
Peter Geoghegan |
| Allow vacuum to reclaim space used by unused trailing heap line pointers |
– |
Mathias van de Ment, Peter Geoghegan |
| Allow vacuum to be more aggressive in removing dead rows during minimal-locking index operations |
Specifically, CREATE INDEX CONCURRENTLY and REINDEX CONCURRENTLY no longer limit the dead row removal of other relations |
Álvaro Herera |
| Speed up vacuuming of databases with many relations |
– |
Tatsuhito Kasahara |
| Reduce the default value of vacuum_cost_page_miss to better reflect current hardware capabilities |
– |
Peter Geoghega |
| Add ability to skip vacuuming of TOAST tables |
VACUUM now has a PROCESS_TOAST option which can be set to false to disable TOAST processing, and vacuumdb has a –no-process-toast option |
Nathan Bosart |
| Have COPY FREEZE appropriately update page visibility bits |
– |
Anastasia Lubenikova, Pavan Deolase, Jef Janes |
| Cause vacuum operations to be more aggressive if the table is near xid or multixact wraparound |
This is controlled by vacuum_failsafe_age and vacuum_multixact_failsafe_age |
Masahiko Sawada, Peter Geoghegan |
| Increase warning time and hard limit before transaction id and multi-transaction wraparound |
This should reduce the possibility of failures that occur without having issued warnings about wraparound |
Noah Misch |
| Add per-index information to autovacuum logging output |
– |
Masahiko Sawada |
Server – partitioning
| Change |
Additional informations |
Author(s) |
| Improve the performance of updates and deletes on partitioned tables with many partitions |
This change greatly reduces the planner’s overhead for such cases, and also allows updates/deletes on partitioned tables to use execution-time partition pruning |
Amit Langote, Tom Lane |
| Allow partitions to be detached in a non-blocking manner |
The syntax is ALTER TABLE … DETACH PARTITION … CONCURRENTLY, and FINALIZE |
Álvaro Herrera |
| Ignore COLLATE clauses in partition boundary values |
Previously any such clause had to match the collation of the partition key; but it’s more consistent to consider that it’s automatically coerced to the collation of the partition key |
Tom Lane |
Server – indexes
| Change |
Additional informations |
Author(s) |
| Allow btree index additions to remove expired index entries to prevent page splits |
This is particularly helpful for reducing index bloat on tables whose indexed columns are frequently updated |
Peter Geoghegan |
| Allow BRIN indexes to record multiple min/max values per range |
This is useful if there are groups of values in each page range |
Tomas Vondra |
| Allow BRIN indexes to use bloom filters |
This allows BRIN indexes to be used effectively with data that is not well-localized in the heap |
Tomas Vondra |
| Allow some GiST indexes to be built by presorting the data |
Presorting happens automatically and allows for faster index creation and smaller indexes |
Andrey Borodin |
| Allow SP-GiST indexes to contain INCLUDE’d columns |
– |
Pavel Borisov |
Server – optimizer
| Change |
Additional informations |
Author(s) |
| Allow hash lookup for IN clauses with many constants |
Previously the code always sequentially scanned the list of values |
James Coleman, David Rowley |
| Increase the number of places extended statistics can be used for OR clause estimation |
– |
Tomas Vondra, Dean Rasheed |
| Allow extended statistics on expressions |
This allows statistics on a group of expressions and columns, rather than only columns like previously. System view pg_stats_ext_exprs reports such statistics |
Tomas Vondra |
| Allow efficient heap scanning of a range of TIDs |
Previously a sequential scan was required for non-equality TID specifications |
Edmund Horner, David Rowley |
| Fix EXPLAIN CREATE TABLE AS and EXPLAIN CREATE MATERIALIZED VIEW to honor IF NOT EXISTS |
Previously, if the object already existed, EXPLAIN would fail |
Bharath Rupireddy |
Server – general performance
| Change |
Additional informations |
Author(s) |
| Improve the speed of computing MVCC visibility snapshots on systems with many CPUs and high session counts |
This also improves performance when there are many idle sessions |
Andres Freund |
| Add executor method to memoize results from the inner side of a nested-loop join |
This is useful if only a small percentage of rows is checked on the inner side. It can be disabled via server parameter enable_memoize |
David Rowley |
| Allow window functions to perform incremental sorts |
– |
David Rowley |
| Improve the I/O performance of parallel sequential scans |
This was done by allocating blocks in groups to parallel workers |
Thomas Munro, David Rowley |
| Allow a query referencing multiple foreign tables to perform foreign table scans in parallel |
postgres_fdw supports this type of scan if async_capable is set |
Robert Haas, Kyotaro Horiguchi, Thomas Munro, Etsuro Fujita |
| Allow analyze to do page prefetching |
This is controlled by maintenance_io_concurrency |
Stephen Frost |
| Improve performance of regular expression searches |
– |
Tom Lane |
| Dramatically improve Unicode normalization |
This speeds normalize() and IS NORMALIZED |
John Naylor |
| Add ability to use LZ4 compression on TOAST data |
This can be set at the column level, or set as a default via server parameter default_toast_compression. The server must be compiled with –with-lz4 to support this feature. The default setting is still pglz |
Dilip Kumar |
Server – monitoring
| Change |
Additional informations |
Author(s) |
| If server parameter compute_query_id is enabled, display the query id in pg_stat_activity, EXPLAIN VERBOSE, csvlog, and optionally in log_line_prefix |
A query id computed by an extension will also be displayed |
Julien Rouhaud |
| Improve logging of auto-vacuum and auto-analyze |
This reports I/O timings for auto-vacuum and auto-analyze if track_io_timing is enabled. Also, report buffer read and dirty rates for auto-analyze |
Stephen Frost, Jakub Wartak |
| Add information about the original user name supplied by the client to the output of log_connections |
– |
Jacob Champion |
Server – system views
| Change |
Additional informations |
Author(s) |
| Add system view pg_stat_progress_copy to report COPY progress |
– |
Josef Šimánek, Matthias van de Meent |
| Add system view pg_stat_wal to report WAL activity |
– |
Masahiro Ikeda |
| Add system view pg_stat_replication_slots to report replication slot activity |
The function pg_stat_reset_replication_slot() resets slot statistics |
Sawada Masahiko, Amit Kapila, Vignesh C |
| Add system view pg_backend_memory_contexts to report session memory usage |
– |
Atsushi Torikoshi, Fujii Masao |
| Add function pg_log_backend_memory_contexts() to output the memory contexts of arbitrary backends |
– |
Atsushi Torikoshi |
| Add session statistics to the pg_stat_database system view |
– |
Laurenz Albe |
| Add columns to pg_prepared_statements to report generic and custom plan counts |
– |
Atsushi Torikoshi, Kyotaro Horiguchi |
| Add lock wait start time to pg_locks |
– |
Atsushi Torikoshi |
| Make the archiver process visible in pg_stat_activity |
– |
Kyotaro Horiguchi |
| Add wait event WalReceiverExit to report WAL receiver exit wait time |
– |
Fujii Masao |
| Implement information schema view routine_column_usage to track columns referenced by function and procedure default expressions |
– |
Peter Eisentraut |
Server – authentication
| Change |
Additional informations |
Author(s) |
| Allow an SSL certificate’s distinguished name (DN) to be matched for client certificate authentication |
The new pg_hba.conf option clientname=DN allows comparison with certificate attributes beyond the CN and can be combined with ident maps |
Andrew Dunstan |
| Allow pg_hba.conf and pg_ident.conf records to span multiple lines |
A backslash at the end of a line allows record contents to be continued on the next line. |
Fabien Coelho |
| Allow the specification of a certificate revocation list (CRL) directory |
This is controlled by server parameter ssl_crl_dir and libpq connection option sslcrldir. Previously only single CRL files could be specified |
Kyotaro Horiguchi |
| Allow passwords of an arbitrary length |
– |
Tom Lane, Nathan Bossart |
Server – server configuration
| Change |
Additional informations |
Author(s) |
| Add server parameter idle_session_timeout to close idle sessions |
This is similar to idle_in_transaction_session_timeout |
Li Japin |
| Change checkpoint_completion_target default to 0.9 |
The previous default was 0.5 |
Stephen Frost |
| Allow %P in log_line_prefix to report the parallel group leader’s PID for a parallel worker |
– |
Justin Pryzby |
| Allow unix_socket_directories to specify paths as individual, comma-separated quoted strings |
Previously all the paths had to be in a single quoted string. |
Ian Lawrence Barwick |
| Allow startup allocation of dynamic shared memory |
This is controlled by min_dynamic_shared_memory. This allows more use of huge pages |
Thomas Munro |
| Add server parameter huge_page_size to control the size of huge pages used on Linux |
– |
Odin Ugedal |
Streaming replication and recovery
| Change |
Additional informations |
Author(s) |
| Allow standby servers to be rewound via pg_rewind |
– |
Heikki Linnakangas |
| Allow the restore_command setting to be changed during a server reload |
You can also set restore_command to an empty string and reload to force recovery to only read from the pg_wal directory |
Sergei Kornilov |
| Add server parameter log_recovery_conflict_waits to report long recovery conflict wait times |
– |
Bertrand Drouvot, Masahiko Sawada |
| Pause recovery on a hot standby server if the primary changes its parameters in a way that prevents replay on the standby |
Previously the standby would shut down immediately |
Peter Eisentraut |
| Add function pg_get_wal_replay_pause_state() to report the recovery state |
It gives more detailed information than pg_is_wal_replay_paused(), which still exists |
Dilip Kumar |
| Add new read-only server parameter in_hot_standby |
This allows clients to easily detect whether they are connected to a hot standby server |
Haribabu Kommi, Greg Nancarrow, Tom Lane |
| Speed truncation of small tables during recovery on clusters with a large number of shared buffers |
– |
Kirk Jamison |
| Allow file system sync at the start of crash recovery on Linux |
By default, PostgreSQL opens and fsyncs each data file in the database cluster at the start of crash recovery. A new setting, recovery_init_sync_method=syncfs, instead syncs each filesystem used by the cluster. This allows for faster recovery on systems with many database files |
Thomas Munro |
| Add function pg_xact_commit_timestamp_origin() to return the commit timestamp and replication origin of the specified transaction |
– |
Movead Li |
| Add the replication origin to the record returned by pg_last_committed_xact() |
– |
Movead Li |
| Allow replication origin functions to be controlled using standard function permission controls |
Previously these functions could only be executed by superusers, and this is still the default |
Martín Marqués |
Streaming replication and recovery – logical replication
| Change |
Additional informations |
Autor/Autorzy |
| Allow logical replication to stream long in-progress transactions to subscribers |
Previously transactions that exceeded logical_decoding_work_mem were written to disk until the transaction completed |
Dilip Kumar, Amit Kapila, Ajin Cherian, Tomas Vondra, Nikhil Sontakke, Stas Kelvich |
| Enhance the logical replication API to allow streaming large in-progress transactions |
The output functions begin with stream. test_decoding also supports these |
Tomas Vondra, Dilip Kumar, Amit Kapila |
| Allow multiple transactions during table sync in logical replication |
– |
Peter Smith, Amit Kapila, and Takamichi Osumi |
| Immediately WAL-log subtransaction and top-level XID association |
This is useful for logical decoding |
Tomas Vondra, Dilip Kumar, Amit Kapila |
| Enhance logical decoding APIs to handle two-phase commits |
This is controlled via pg_create_logical_replication_slot() |
Ajin Cherian, Amit Kapila, Nikhil Sontakke, Stas Kelvich |
| Generate WAL invalidation messages during command completion when using logical replication |
When logical replication is disabled, WAL invalidation messages are generated at transaction completion. This allows logical streaming of in-progress transactions |
Dilip Kumar, Tomas Vondra, Amit Kapila |
| Allow logical decoding to more efficiently process cache invalidation messages |
This allows logical decoding to work efficiently in presence of a large amount of DDL |
Dilip Kumar |
| Allow control over whether logical decoding messages are sent to the replication stream |
– |
David Pirotte, Euler Taveira |
| Allow logical replication subscriptions to use binary transfer mode |
This is faster than text mode, but slightly less robust |
Dave Cramer |
| Allow logical decoding to be filtered by XID |
– |
Markus Wanner |
SELECT, INSERT
| Change |
Additional informations |
Author(s) |
| Reduce the number of keywords that can’t be used as column labels without AS |
There are now 90% fewer restricted keywords |
Mark Dilger |
| Allow an alias to be specified for JOIN’s USING clause |
The alias is created by writing AS after the USING clause. It can be used as a table qualification for the merged USING columns |
Peter Eisentraut |
| Allow DISTINCT to be added to GROUP BY to remove duplicate GROUPING SET combinations |
For example, GROUP BY CUBE (a,b), CUBE (b,c) will generate duplicate grouping combinations without DISTINCT |
Vik Fearing |
| Properly handle DEFAULT entries in multi-row VALUES lists in INSERT |
Such cases used to throw an error. |
Dean Rasheed |
| Add SQL-standard SEARCH and CYCLE clauses for common table expressions |
The same results could be accomplished using existing syntax, but much less conveniently |
Peter Eisentraut |
| Allow column names in the WHERE clause of ON CONFLICT to be table-qualified |
Only the target table can be referenced, however |
Tom Lane |
Utility commands
| Change |
Additional informations |
Author(s) |
| Allow REFRESH MATERIALIZED VIEW to use parallelism |
– |
Bharath Rupireddy |
| Allow REINDEX to change the tablespace of the new index |
This is done by specifying a TABLESPACE clause. A –tablespace option was also added to reindexdb to control this |
Alexey Kondratov, Michael Paquier, Justin Pryzby |
| Allow REINDEX to process all child tables or indexes of a partitioned relation |
– |
Justin Pryzby, Michael Paquier |
| Allow index commands using CONCURRENTLY to avoid waiting for the completion of other operations using CONCURRENTLY |
– |
Álvaro Herrera |
| Improve the performance of COPY FROM in binary mode |
– |
Bharath Rupireddy, Amit Langote |
| Preserve SQL standard syntax for SQL-defined functions in view definitions |
Previously, calls to SQL-standard functions such as EXTRACT() were shown in plain function-call syntax. The original syntax is now preserved when displaying a view or rule |
Tom Lane |
| Add the SQL-standard clause GRANTED BY to GRANT and REVOKE |
– |
Peter Eisentraut |
| Add OR REPLACE option for CREATE TRIGGER |
This allows pre-existing triggers to be conditionally replaced |
Takamichi Osumi |
| Allow TRUNCATE to operate on foreign tables |
The postgres_fdw module also now supports this |
Kazutaka Onishi, Kohei KaiGai |
| Allow publications to be more easily added to and removed from a subscription |
The new syntax is ALTER SUBSCRIPTION … ADD/DROP PUBLICATION. This avoids having to specify all publications to add/remove entries |
Japin Li |
| Add primary keys, unique constraints, and foreign keys to system catalogs |
These changes help GUI tools analyze the system catalogs. The existing unique indexes of catalogs now have associated UNIQUE or PRIMARY KEY constraints. Foreign key relationships are not actually stored or implemented as constraints, but can be obtained for display from the function pg_get_catalog_foreign_keys() |
Peter Eisentraut |
| Allow CURRENT_ROLE every place CURRENT_USER is accepted |
– |
Peter Eisentraut |
Data types
| Change |
Additional informations |
Author(s) |
| Allow extensions and built-in data types to implement subscripting |
Previously subscript handling was hard-coded into the server, so that subscripting could only be applied to array types. This change allows subscript notation to be used to extract or assign portions of a value of any type for which the concept makes sense |
Dmitry Dolgov |
| Allow subscripting of JSONB |
JSONB subscripting can be used to extract and assign to portions of JSONB documents |
Dmitry Dolgov |
| Add support for multirange data types |
These are like range data types, but they allow the specification of multiple, ordered, non-overlapping ranges. An associated multirange type is automatically created for every range type |
Paul Jungwirth, Alexander Korotkov |
| Add support for the stemming of languages Armenian, Basque, Catalan, Hindi, Serbian, and Yiddish |
– |
Peter Eisentraut |
| Allow tsearch data files to have unlimited line lengths |
The previous limit was 4K bytes. Also remove function t_readline() |
Tom Lane |
| Add support for Infinity and -Infinity values in the numeric data type |
Floating-point data types already supported these |
Tom Lane |
| Add point operators <<| and |>> representing strictly above/below tests |
Previously these were called >^ and <^, but that naming is inconsistent with other geometric data types. The old names remain available, but may someday be removed |
Emre Hasegeli |
| Add operators to add and subtract LSN and numeric (byte) values |
– |
Fujii Masao |
| Allow binary data transfer to be more forgiving of array and record OID mismatches |
– |
Tom Lane |
| Create composite array types for system catalogs |
User-defined relations have long had composite types associated with them, and also array types over those composite types. System catalogs now do as well. This change also fixes an inconsistency that creating a user-defined table in single-user mode would fail to create a composite array type |
Wenjing Zeng |
Functions
| Change |
Additional informations |
Author(s) |
| Allow SQL-language functions and procedures to use SQL-standard function bodies |
Previously only string-literal function bodies were supported. When writing a function or procedure in SQL-standard syntax, the body is parsed immediately and stored as a parse tree. This allows better tracking of function dependencies, and can have security benefits |
Peter Eisentraut |
| Allow procedures to have OUT parameters |
– |
Peter Eisentraut |
| Allow some array functions to operate on a mix of compatible data types |
The functions array_append(), array_prepend(), array_cat(), array_position(), array_positions(), array_remove(), array_replace(), and width_bucket() now take anycompatiblearray instead of anyarray arguments. This makes them less fussy about exact matches of argument types |
Tom Lane |
| Add SQL-standard trim_array() function |
This could already be done with array slices, but less easily |
Fearing |
| Add bytea equivalents of ltrim() and rtrim() |
– |
Joel Jacobson |
| Support negative indexes in split_part() |
Negative values start from the last field and count backward |
Nikhil Benesch |
| Add string_to_table() function to split a string on delimiters |
This is similar to the regexp_split_to_table() function |
Pavel Stehule |
| Add unistr() function to allow Unicode characters to be specified as backslash-hex escapes in strings |
This is similar to how Unicode can be specified in literal strings |
Pavel Stehule |
| Add bit_xor() XOR aggregate function |
– |
Alexey Bashtanov |
| Add function bit_count() to return the number of bits set in a bit or byte string |
– |
David Fetter |
| Add date_bin() function |
This function “bins” input timestamps, grouping them into intervals of a uniform length aligned with a specified origin |
John Naylor |
| Allow make_timestamp()/make_timestamptz() to accept negative years |
Negative values are interpreted as BC years |
Peter Eisentraut |
| Add newer regular expression substring() syntax |
The new SQL-standard syntax is SUBSTRING(text SIMILAR pattern ESCAPE escapechar). The previous standard syntax was SUBSTRING(text FROM pattern FOR escapechar), which is still accepted by PostgreSQL |
Peter Eisentraut |
| Allow complemented character class escapes , , and within regular expression brackets |
– |
Tom Lane |
| Add [[:word:]] as a regular expression character class, equivalent to |
– |
Tom Lane |
| Allow more flexible data types for default values of lead() and lag() window functions |
– |
Vik Fearing |
| Make non-zero floating-point values divided by infinity return zero |
Previously such operations produced underflow errors |
Kyotaro Horiguchi |
| Make floating-point division of NaN by zero return NaN |
Previously this returned an error |
Tom Lane |
| Cause exp() and power() for negative-infinity exponents to return zero |
Previously they often returned underflow errors |
Tom Lane |
| Improve the accuracy of geometric computations involving infinity |
– |
Tom Lane |
| Mark built-in type coercion functions as leakproof where possible |
This allows more use of functions that require type conversion in security-sensitive situations |
Tom Lane |
| Change pg_describe_object(), pg_identify_object(), and pg_identify_object_as_address() to always report helpful error messages for non-existent objects |
– |
Michael Paquier |
PL/pgSQL
| Change |
Additional informations |
Autor/Autorzy |
| Improve PL/pgSQL’s expression and assignment parsing |
This change allows assignment to array slices and nested record fields |
Tom Lane |
| Allow plpgsql’s RETURN QUERY to execute its query using parallelism |
– |
Tom Lane |
| Improve performance of repeated CALLs within plpgsql procedures |
– |
Pavel Stehule, Tom Lane |
Client interfaces
| Change |
Additional informations |
Author(s) |
| Add pipeline mode to libpq |
This allows multiple queries to be sent, only waiting for completion when a specific synchronization message is sent |
Craig Ringer, Matthieu Garrigues, Álvaro Herrera |
| Enhance libpq’s target_session_attrs parameter options |
The new options are read-only, primary, standby, and prefer-standby |
Haribabu Kommi, Greg Nancarrow, Vignesh C, Tom Lane |
| Improve the output format of libpq’s PQtrace() |
– |
Aya Iwata, Álvaro Herrera |
| Allow an ECPG SQL identifier to be linked to a specific connection |
This is done via DECLARE … STATEMENT |
Hayato Kuroda |
Client applications
| Change |
Additional informations |
Author(s) |
| Allow vacuumdb to skip index cleanup and truncation |
The options are –no-index-cleanup and –no-truncate |
Nathan Bossart |
| Allow pg_dump to dump only certain extensions |
This is controlled by option –extension |
Guillaume Lelarge |
| Add pgbench permute() function to randomly shuffle values |
– |
Fabien Coelho, Hironobu Suzuki, Dean Rasheed |
| Include disconnection times in the reconnection overhead measured by pgbench with -C |
– |
Yugo Nagata |
| Allow multiple verbose option specifications (-v) to increase the logging verbosity |
This behavior is supported by pg_dump, pg_dumpall, and pg_restore |
Tom Lane |
Client applications – psql
| Change |
Additional informations |
Autor/Autorzy |
| Allow psql’s and commands to specify function and operator argument types |
This helps reduce the number of matches printed for overloaded names |
Greg Sabino Mullane, Tom Lane |
| Add an access method column to psql’s + output |
– |
Georgios Kokolatos |
| Allow psql’s and to show TOAST tables and their indexes |
– |
Justin Pryzby |
| Add psql command to list extended statistics objects |
– |
Tatsuro Yamada |
| Fix psql’s to understand array syntax and backend grammar aliases, like int for integer |
– |
Greg Sabino Mullane, Tom Lane |
| When editing the previous query or a file with psql’s , or using and , ignore the results if the editor exits without saving |
Previously, such edits would load the previous query into the query buffer, and typically execute it immediately. This was deemed to be probably not what the user wants |
Laurenz Albe |
| Improve tab completion |
– |
Vignesh C, Michael Paquier, Justin Pryzby, Georgios Kokolatos, Julien Rouhaud |
Server applications
| Change |
Additional informations |
Author(s) |
| Add command-line utility pg_amcheck to simplify running contrib/amcheck tests on many relations |
– |
Mark Dilger |
| Add –no-instructions option to initdb |
This suppresses the server startup instructions that are normally printed |
Magnus Hagander |
| Stop pg_upgrade from creating analyze_new_cluster script |
Instead, give comparable vacuumdb instructions |
Magnus Hagander |
| Remove support for the postmaster -o option |
This option was unnecessary since all passed options could already be specified directly |
Magnus Hagander |
Documentation
| Change |
Additional informations |
Author(s) |
| Rename “Default Roles” to “Predefined Roles” |
– |
Bruce Momjian, Stephen Frost |
| Add documentation for the factorial() function |
With the removal of the ! operator in this release, factorial() is the only built-in way to compute a factorial |
Peter Eisentraut |
Source code
| Change |
Additional informations |
Autor/Autorzy |
| Add configure option –with-ssl={openssl} to allow future choice of the SSL library to use |
The spelling –with-openssl is kept for compatibility |
Daniel Gustafsson, Michael Paquier |
| Add support for abstract Unix-domain sockets |
This is currently supported on Linux and Windows |
Peter Eisentraut |
| Allow Windows to properly handle files larger than four gigabytes |
For example this allows COPY, WAL files, and relation segment files to be larger than four gigabytes |
Juan José Santamaría Flecha |
| Add server parameter debug_discard_caches to control cache flushing for test purposes |
Previously this behavior could only be set at compile time. To invoke it during initdb, use the new option –discard-caches |
Craig Ringer |
| Various improvements in valgrind error detection ability |
– |
Álvaro Herrera, Peter Geoghegan |
| Add a test module for the regular expression package |
– |
Tom Lane |
| Add support for LLVM version 12 |
– |
Andres Freund |
| Change SHA1, SHA2, and MD5 hash computations to use the OpenSSL EVP API |
This is more modern and supports FIPS mode |
Michael Paquier |
| Remove separate build-time control over the choice of random number generator |
This is now always determined by the choice of SSL library |
Daniel Gustafsson |
| Add direct conversion routines between EUC_TW and Big5 encodings |
– |
Heikki Linnakangas |
| Add collation version support for FreeBSD |
– |
Thomas Munro |
| Add amadjustmembers to the index access method API |
This allows an index access method to provide validity checking during creation of a new operator class or family |
Tom Lane |
| Provide feature-test macros in libpq-fe.h for recently-added libpq features |
Historically, applications have usually used compile-time checks of PG_VERSION_NUM to test whether a feature is available. But that’s normally the server version, which might not be a good guide to libpq’s version. libpq-fe.h now offers #define symbols denoting application-visible features added in v14; the intent is to keep adding symbols for such features in future versions |
Tom Lane, Álvaro Herrera |
Additional modules
| Change |
Additional informations |
Author(s) |
| Allow subscripting of hstore values |
– |
Tom Lane, Dmitry Dolgov |
| Allow GiST/GIN pg_trgm indexes to do equality lookups |
This is similar to LIKE except no wildcards are honored |
Julien Rouhaud |
| Allow the cube data type to be transferred in binary mode |
– |
KaiGai Kohei |
| Allow pgstattuple_approx() to report on TOAST tables |
– |
Peter Eisentraut |
| Add contrib module pg_surgery which allows changes to row visibility |
This is useful for correcting database corruption |
Ashutosh Sharma |
| Add contrib module old_snapshot to report the XID/time mapping used by an active old_snapshot_threshold |
– |
Robert Haas |
| Allow amcheck to also check heap pages |
Previously it only checked B-Tree index pages |
Mark Dilger |
| Allow pageinspect to inspect GiST indexes |
– |
Andrey Borodin, Heikki Linnakangas |
| Change pageinspect block numbers to be bigints |
– |
Peter Eisentraut |
| Mark btree_gist functions as parallel safe |
– |
Steven Winfield |
Additional modules – pg_stat_statements
| Change |
Additional informations |
Author(s) |
| Move query hash computation from pg_stat_statements to the core server |
The new server parameter compute_query_id’s default of auto will automatically enable query id computation when this extension is loaded |
Julien Rouhaud |
| Cause pg_stat_statements to track top and nested statements separately |
Previously, when tracking all statements, identical top and nested statements were tracked as a single entry; but it seems more useful to separate such usages |
Julien Rohaud |
| Add row counts for utility commands to pg_stat_statements |
– |
Fujii Masao, Katsuragi Yuta, Seino Yuki |
| Add pg_stat_statements_info system view to show pg_stat_statements activity |
– |
Katsuragi Yuta, Yuki Seino, Naoki Nakamichi |
Additional modules – postgres_fdw
| Change |
Additional informations |
Author(s) |
| Allow postgres_fdw to INSERT rows in bulk |
– |
Takayuki Tsunakawa, Tomas Vondra, Amit Langote |
| Allow postgres_fdw to import table partitions if specified by IMPORT FOREIGN SCHEMA … LIMIT TO |
By default, only the root of a partitioned table is imported |
Matthias van de Meent |
| Add postgres_fdw function postgres_fdw_get_connections() to report open foreign server connections |
– |
Bharath Rupireddy |
| Allow control over whether foreign servers keep connections open after transaction completion |
This is controlled by keep_connections and defaults to on |
Bharath Rupireddy |
| Allow postgres_fdw to reestablish foreign server connections if necessary |
Previously foreign server restarts could cause foreign table access errors |
Bharath Rupireddy |
| Add postgres_fdw functions to discard cached connections |
– |
Bharath Rupireddy |
Further development
The above list of new features in PostgreSQL shows constant development and commitment of many communities, whose goal is to create the best, the fastest and always free database engine. We will be happy to follow Postgres development and keep you informed of any news.

 2021-11-10
2021-11-10
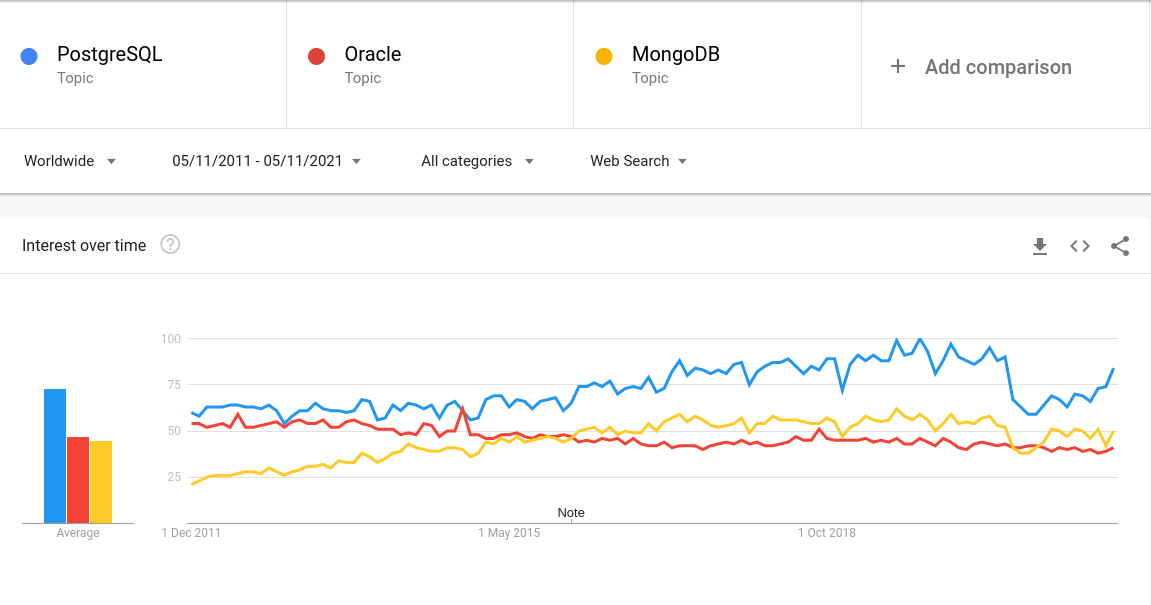 The graph shows interest over time – the peak of popularity of a topic in Google searches was marked as 100. A value of 50 means that the topic was half as popular.
The graph shows interest over time – the peak of popularity of a topic in Google searches was marked as 100. A value of 50 means that the topic was half as popular.